
Fanpool
Founding Engineer / Product Engineer NestJS, React, MongoDB, Circle Programmable Wallets, AWS | 2023 — 2025
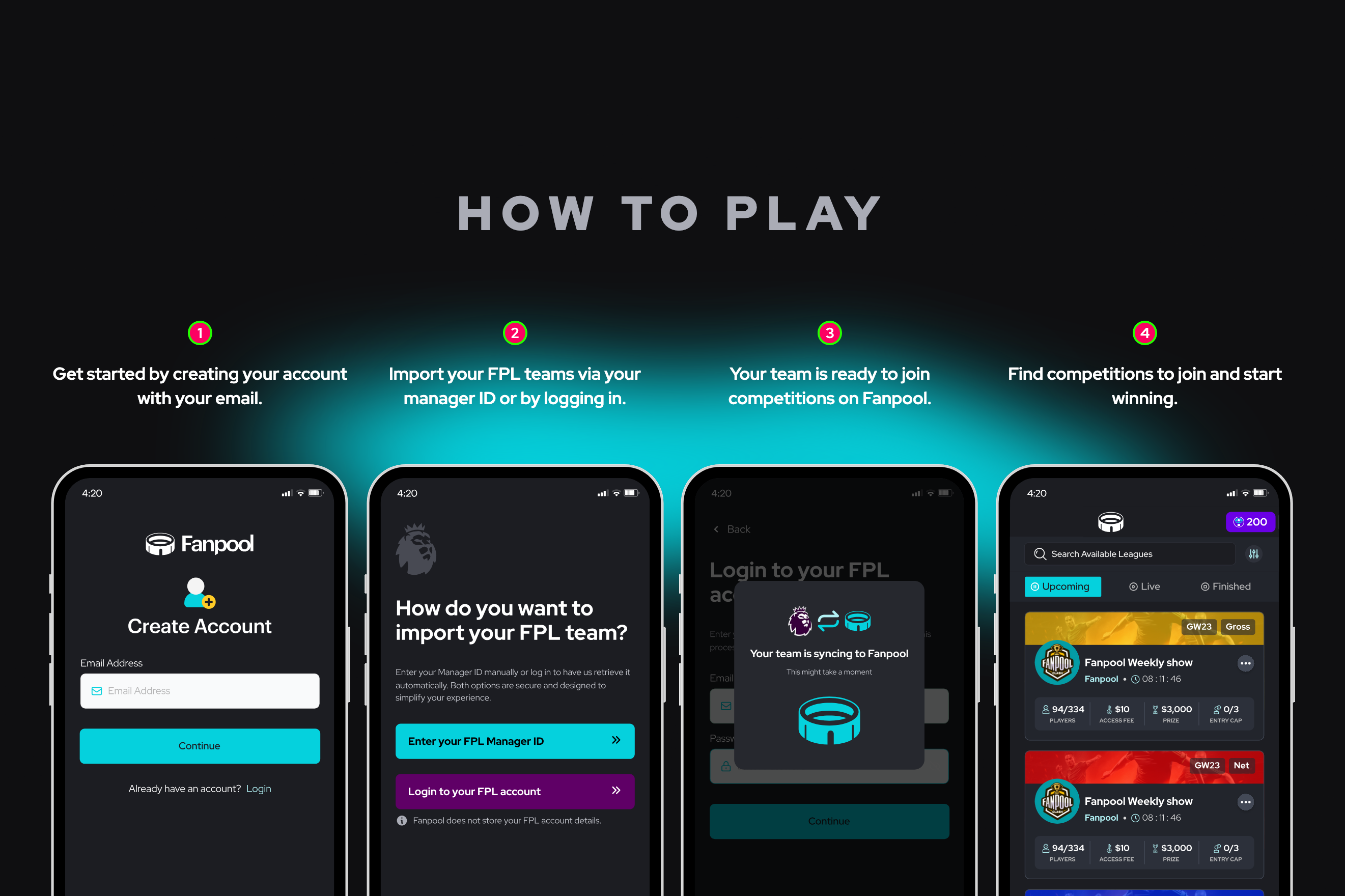
TL;DR > I architected and built Fanpool, a P2P fantasy football platform that replaced manual, "spreadsheet-based" pools with an automated, Web3-powered system. I owned the product end-to-end, growing it to 2,000+ users, securing Circle grants, and processing thousands of dollars in global USDC payouts.
The Problem
- The Trust Gap: The FPL community is massive, but private prize pools were managed manually via spreadsheets. This led to transparency issues and payout delays.
- Global Friction: Traditional fiat rails made cross-border participation impossible. FPL fans in Nigeria, Saudi Arabia, and the UK couldn't easily compete in the same pool.
- Data Complexity: The FPL API is undocumented and updates in irregular bursts. Aggregating this data for multi-week competitions at scale is a non-trivial state-management challenge.
My Role & Ownership
As the Founding Engineer, I was responsible for the technical roadmap and execution:
- System Architecture: Designed a decoupled NestJS backend to handle high-frequency data ingestion and prize distribution.
- FinOps: Integrated Circle’s Programmable Wallets to automate escrow and prize payouts.
- Data Engineering: Built the core engine for retrieving, sanitizing, and aggregating live FPL data.
- Product Delivery: Led the transition from a monolithic MVP to a modular, scalable production application.
Key Technical Decisions
-
Circle Wallets
Why? Avoided building custom custodial infrastructure from scratch.
Impact: Saved 3+ months of dev time; secured technical support/grants from Circle. -
USDC via Solana
Why? Needed near-instant global settlement with negligible gas fees.
Impact: Enabled a borderless user base (Africa, Middle East, Europe) without FX headaches. -
Modular Payouts
Why? Separated “Score Calculation” from “Fund Distribution.”
Impact: Prevented partial payout failures and ensured 100% accounting accuracy.
Deep Dive: Real-Time Multi-Week Aggregation
The Challenge
FPL data is "chunky." During matchdays, thousands of players' scores update simultaneously. Our initial architecture was tightly coupled—writing scores for a 38-week competition required massive recursive updates that locked the database and caused UI lag.
Constraints
- Scale: Handling 200+ unique entries per competition across multiple concurrent leagues.
- API Behavior: The source API is read-only and lacks webhooks, requiring efficient polling strategies.
The Solution: Non-Blocking Managers
I re-engineered the system to decouple Competitions from Scoreboards.
- I built a non-blocking update manager that processed gameweek data in batches.
- Used ACID transactions to aggregate total competition points independently of individual gameweek writes.
- Implemented a caching layer so "Live Points" were served instantly without hitting the primary DB.
The result: Points updated almost instantly across the app. This performance boost led directly to partnerships with brands who felt confident hosting large-scale sponsored competitions.
What Didn’t Work (And How I Fixed It)
Early Mistake: Tight Coupling I initially designed the architecture assuming competitions would be short-term. When we introduced season-long games, the "top-down" write approach became a bottleneck.
The Pivot: I executed a full redesign of the competition/scoreboard modules in one week. By decoupling these entities, I eliminated data inconsistency and improved aggregation speed by over 400%.
What I’d Do Differently: Choosing the Right DB
If I rebuilt this today, I would choose Postgres over MongoDB. We chose MongoDB early on for its schema flexibility, but as the product matured, we hit two major pain points:
-
The JSONB Advantage: We handled complex, nested data like rankings and per-gameweek snapshots using TypeScript interfaces that matched MongoDb Types. However, relying on application-level types didn't offer the same efficiency as Postgres'
JSONB. With JSONB, I could have indexed specific keys within a ranking object, allowing for high-performance leaderboard queries and analytics without the overhead of the "schema-less" flexibility that Mongo provides. -
Unique Sparse Indexes: In MongoDB,
nullvalues are treated as a single unique value. To support our data model using Prisma, I had to bypass the ORM and write custom native drivers to handle sparse indexes:
// Custom utility to handle MongoDB's unique index limitations for nullable fields
private async ensureIndexes() {
const client = new MongoClient(process.env.DATABASE_URL!);
try {
await client.connect();
const db = client.db();
// Creating a sparse unique index to ignore nulls
await db.collection('Competitions').createIndex(
{ externalId: 1 },
{ unique: true, sparse: true, name: "comp_externalId_unique" }
);
this.logger.log('Critical MongoDB indexes optimized.');
} finally {
await client.close();
}
}Outcomes
- Shipped & Proven: Successfully managed thousands of dollars in entry fees and payouts with zero loss of funds.
- Growth: Scaled to 2,000+ users with high retention on matchdays.
- Institutional Trust: Secured official grants and technical backing from the Circle team.
- Product-Ready: Created a modular, optimized architecture that allowed growth and development speed.
What This Prepared Me For
Building Fanpool from 0 to 1 taught me how to:
- Own systems end-to-end in high-stakes environments (handling real money).
- Balance speed with correctness—knowing when to hack and when to over-engineer.
- Work as a partner to founders, translating business goals (global expansion) into technical decisions.
- Website: https://fanpool.gg
Fanpool was eventually sunset due to business pivots, but the engineering challenges I solved there remain my most significant "battle-tested" experiences.
If you’re building an early-stage product and need an engineer who can own both infrastructure and product delivery, I’d be happy to chat.